André-Jacob ROUBO - Le Forum
Le mieux qu'il est possible.
Vous n'êtes pas identifié(e).
- Contributions : Récentes | Sans réponse
Pages : 1
#1 22/03/2018 18:15
- jrbastien
- Membre
- Inscription : 19/03/2018
- Messages : 20
OCR de l'Art du Menuisier
Comme vous le savez j'ai entrepris la correction du ePub fournit par l'Intenet Archive afin d'avoir une version électronique de l'art du Menuisier.
J'en suis présentement au Chapitre 6 et c'est très long.
Après quelques tests d'OCR avec Tesseract, je me suis aperçu qu'en utilisant l'option de langage frm (Français moyen - médévial), les résultats sont bien meilleurs.
Je vais donc repartir des pages individuelles et produire un nouvel OCR pour les prochains chapitres.
Mes questions:
Pour les besoins de ce site, quel est le meilleur format (avec mise en page) ou texte pur?
Quel serait le meilleur site pour pouvoir obtenir la collaboration de d'autres correcteurs? Personnellement j'utilise GitHub, ça permet de conserver l'historique et d'approuver les "Pull Requests"
Connaissez vous un correcteur orthographique qui supporte les s longs? Pour l'instant, j'utilise Sigil pour trouver les erreurs mais il ne connaît rien à cette forme ancienne d'écriture. Remarquez que je crois avoir défini les règles de conversions dans la discussion précédente. J'attends votre confirmation.
Jean-René
Dernière modification par jrbastien (22/03/2018 18:54)
Hors ligne
#2 26/03/2018 00:00

Re : OCR de l'Art du Menuisier
Vous n’ignorez certainement pas qu’un fichier e-pub n’est rien d’autre qu’un fichier zip dont on a simplement changé l’extension « .zip » pour « .epub ». Si votre système d’exploitation le permet simplement sans trop râler, faite le renommage inverse et vous pourrez extraire tous les fichiers contenus dans cette archive. Cette extraction faite, vous pourrez jouer les curieux, par exemple aller dans le dossier (répertoire) nommé « OEBPS/Text ». Et vous rendre compte, là, que ce ne sont que de SIMPLES fichiers (x)HTML, tout ce qu’il y a de plus courants. Donc ce n’est rien d’autre qu’un site Web, tel que le présent, avec des liens, des fichiers de style (CSS), soit une version très proche de ce genre de page !
Par courriel, vous me citiez trois avantages de l’e-pub, à savoir :
Navigation grâce à la table des matières.
Utilisation d'italique comme dans l'ouvrage original
Utilisation de petites capitales comme dans l'ouvrage original.
Tout cela est évidement présent en HTML le plus cru.
Maintenant il me semble qu’on est (très) loin de devoir s’occuper de mise en place d’un e-pub, au pesé, non seulement du texte disponible, mais de l’abondance de ses correcteurs. Comme je suis une personne pleine de vices, perverse et méchante, je vais, forcément, illustrer mon propos. Il ne s’agit que de votre transcription des trois pages de l’« Avant-propos », parce que je n’ai pas pris le temps de relire le reste. Ce fichier PDF est d’une méchanceté crasse ; le genre qui vous mettra le moral à zéro. Vous allez détester la couleur orange, à fortiori parce que, de votre version passée de manière privative, je n’ai volontairement corrigé aucun s long, uniquement quelques espaces insécables (typiquement Louis_XIII), aucune apostrophe (vous utilisez la très laide apostrophe dactylographique, petite crotte américaine, alors que la typographique, toute en rondeur, est juste ... aussi élégante que l’époque de notre auteur) et d’autres bricoles... Tout cela fait que ce texte n’est, à mes yeux, aussi déjà fortement avancé dans son traitement qu’encore loin d’être prêt pour être fixé dans le marbre (toutefois toujours corrigeable) HTML.
Vous me lisez toujours ? Vous n’avez pas défoncé votre écran, de rage, au pointage de mes sodomies de diptères ? Beatus Vir ! D’abord sachez que je ne prends JAMAIS le temps d’expliquer à quelqu’un ses erreurs si je ne suis pas, aussi, en mesure d’apprécier son travail par ailleurs. Il vous faut savoir que tout cela est PARFAITEMENT NORMAL pour un texte dont la relecture n’a eu lieu que par UNE personne et, sans doute, pas assez de fois. Rassurez vous aussi sur le fait que je suis quasiment sûr qu’il y a moins de fautes de retranscription au fur et à mesure de l’avancement de vos chapitres même si je n’ai pas pris le temps de vérifier ce point précis. Le regard s’aiguise et se forme ; comme le reste, c’est normal.
Ainsi, je crois pour ma part, que bien avant de produire un e-pub, il faut que le texte soit considéré irréprochable et, pour cela, être modifiable facilement, par exemple dans un traitement de texte. Vous aurez compris que je suis particulièrement à l’aise, depuis des années maintenant, dans le langage des macros de LibreOffice/OpenOffice. Mon niveau est suffisant pour nager dans des eaux comme le D.O.M., même utilisé par le simple Basic de la suite bureautique. C’est au-delà de ce que peut nous offrir la suite propriétaire (celle de « vous savez qui »).
Vous semblez très attaché à faire en sorte de rendre ce travail collaboratif. Vous aurez compris, je l’espère, que je suis, sinon dans vos pas, sans doute vous précédant dans ce chemin qui reste ardu. Mais je suis, aussi, très instruit d’expérience de la niche dans laquelle nous nous trouvons. Les éditeurs collaboratifs existent ; je ne citerai qu’Etherpad mais nous pouvons en trouver d’autres. J’aime assez et quand même, maîtriser ma petite chaîne éditoriale... Je veux dire que si on prend par exemple Framapad (qui est un Etherpad light), il faut quand même noter qu’il est dans les choux depuis un certain temps... roubo.art est hébergé chez Ouvaton ; actuellement, c’est très difficile de mettre ça en place sur un hébergement mutualisé. Donc j’y pense (à cela précisément ou une solution du même genre), mais je n’ai sérieusement pas assez d’arguments pour me convaincre qu’il y ait, ici, urgence.
Je me dois maintenant de répondre ENFIN à vos questions...
Le plus simple est, pour le moment, de produire des fichiers Writer (.odt), soit dans le format ODF. Vous notez que la mise en page est, dans une page Web comme dans un e-pub, totalement dynamique (au contraire d’un PDF). Un exemple peut se faire jour si vous affichez cette page et que vous réduisez votre fenêtre de navigateur Web en largeur. Jusqu’à un certain point, vous n’aurez pas besoin de vous servir de l’« ascenseur horizontal » puisque c’est la mise en page même des deux colonnes qui s’adaptera systématiquement à la largeur de votre fenêtre. Il n’est donc pas nécessaire, pour le moment, de s’attacher trop à la mise en page, excepté, peut être, les centrés (mais ils ne sont en usage que dans les titres). C’est bien entendu tout le contraire pour ce qui regarde les enrichissements (gras, italique souligné). Roubo ne connaît quasiment que l’italique et, parfois, certaines mises en exposant. Tout cela me semble secondaire, dans l’état actuel des choses étant quand même donné que le travail le plus difficile relève de la relecture et d’une méthodologie extrêmement rigoureuse entre les personnes, de façon à ce qu’une opération ne soit pas faite deux fois pour rien.
Je connais mal ces éditeurs mainstream dont je me méfie comme de La Peste. J’entends bien que si nous étions ne serait-ce que trois ou quatre dans cette aventure, l’évolution sur ce type de plateforme puisse s’imposer. Mais nous n’y sommes évidement pas et ma todo-list-à-moi, c’est de nettoyer les Planches de L’Art du Menuisier dans l’année qui vient, sans doute en débordant un peu sur la suivante. Le présent forum est là pour afficher les questions qui se posent à nous de façon à montrer au public nos interrogations et nos difficultés. Il nous faut, il me semble, être plus que seulement deux personnes pour envisager cette évolution-là. Cela me fait vous répéter ici ce que je vous ai déjà écrit en privé : Rome ne s’est pas faite en un jour... Donc s’il advenait, dans l’année, qu’un autre relecteur se mette dans la compagnie alors on penserait évidement à une méthodologie communautaire. Mais pour l’instant, je m’occupe des Planches... Par contre, prenez bien conscience que votre travail, dans l’état actuel et pour m’y être penché dessus un peu au-delà du simple « Avant-propos » reste, tout de même, ce qui se fait de mieux actuellement. Nous pouvons le mettre en ligne sur le présent site dans son état actuel sous forme de fichiers Writer, téléchargeables directement, voire sous GitHub si vous le préférez. J’aurai, pour ma part, évidemment tendance à largement préférer Wikisource qui possède, aussi, un système d’archivage. Mais je n’y suis pas et les journées n’ont que 24 heures !
Au pesé des spécificités des textes du XVIIIe siècle, je ne crois pas qu’un correcteur orthographique puisse vous être vraiment utile ; je pense même qu’il induit en erreur. Nous avons vu ailleurs qu’il est effectivement assez simple de revenir aux s longs et que ce n’est finalement qu’une simple manipulation technique. J’utilise pour ma part l’excellente extension Grammalecte sans jamais m’être préoccupé de l’adapter au Français de l’Ancien Régime. C’est peut-être possible, mais cette extension est principalement codée en Python, qui m’est (malheureusement) encore trop une « terra incognita » pour que je prenne le temps d’aller m’y perdre...
Merci beaucoup à vous de m’avoir fait découvrir « Tesseract » dont j’ignorais jusqu’à l’existence et de nous témoigner de l’existence de l’option de langage frm et de son efficience par vous constatée. C’est toujours autant de temps gagné pour ceux qui iront dans votre sens et le fait que ce soit écrit en ce lieu, fait, forcément, avancer les choses.
Dans tous les cas, le maître-mot qu’il est capital de retenir c’est cette morale de La Fontaine : « Patience et longueur de temps font plus que force ni que rage »...
Hors ligne
#3 26/03/2018 18:14
- jrbastien
- Membre
- Inscription : 19/03/2018
- Messages : 20
Re : OCR de l'Art du Menuisier
Merci pour ces réponses. Je vais les approfondir plus en détails lorsque je serai prêt.
Refaire l'OCR ne m'avance pas car je dois refaire tout le formatage. Pour l'instant je fais plus de tests de OCR et post-traitement avec bash. Mais je vais peut-être me mettre à la programmation Python pour plus de contrôle.
Et effectivement, l'avant-propos était mes premières armes à ce texte. Je commence maintenant à vivre et penser comme Roubo après plus de 10 chapitres.
Hors ligne
#4 08/04/2018 04:33
- jrbastien
- Membre
- Inscription : 19/03/2018
- Messages : 20
Re : OCR de l'Art du Menuisier
Bonjour, je viens de relire ce flot de mots et je ne m'étais pas rendu compte que vous m'aviez fourni une correction de l'avant-propos en format PDF. Avec le recul, je m'aperçois que je me suis amélioré mais vous avez raison, il y a sûrement encore beaucoup d'erreurs à rectifier.
Cela me donne une idée, il est sans doute possible d'éditer le dictionnaire de Sigil que j'utilise pour éviter qu'il accepte des mots orthographiés de façon moderne.
Pour ce qui est du statut de ma numérisation, j'ai complété les 11 chapitres de la première partie et le premier de la seconde. Et je continue mes expériences de programmation tout en faisant cela.
Je désire toujours publier le tout sous forme de eBook mais je vous fournirai en parallèle le résultat de mes travaux.
Hors ligne
#5 08/04/2018 11:57
Re : OCR de l'Art du Menuisier
Bonjour Jean-René !
Merci pour votre texte de blog ! C’est aussi très gentil !
Avant de vous assommer de mes commentaires, je vais, moi aussi, prendre le temps d’étudier et de lire votre travail, qu’encore une fois, je sais approfondi pour en avoir eu un aperçu déjà très précis et connaître parfaitement de quelles peines il relève. Nos deux approches sont différentes ; cela les rend que plus intéressantes de par l’émulation qui en résulte.
Je vais faire un tutoriel détaillé pour l’usage de ce qui suit mais votre niveau d’informatique est largement suffisant pour pouvoir s’en passer. C’est aussi ce qui me pousse à vous montrer, un peu en avant première, un petit travail, en fait incité par vous...
Voilà, j’ai pris l’OCR d’Internet Archive et je l’ai, simplement, copié-collé dans un fichier Writer. J’ai choisi de ne travailler, à titre d’exemple, que sur les deux premiers Chapitres de la Seconde Partie et les deux premières Sections du troisième Chapitre. J’ai choisi ce texte parce qu’il fait environ cinquante pages, un peu plus avant traitement, un peu moins après. Le fichier en question est disponible ici. Il est exempt de macro.
J’ai repris la macro dont je vous ai parlé ailleurs et l’ai, cette fois, parfaitement adaptée à l’usage du sieur Roubo. Je ne saurai, quand même, que trop vous inciter de faire un essai... Vous devez d’abord ouvrir le fichier Writer qui contient l’OCR d’Internet Archive. Si vous le faites après, alors cliquez sur le bouton « Rafraîchir la liste des fichiers texte (Writer) » pour qu’il apparaisse bien en cellule B6-C6. Une fois le fichier spécifié le fichier dans cette cellule (une liste déroulante est à votre disposition), un petit clic sur le bouton « Action ! » et, selon la rapidité de votre machine (la mienne est antédiluvienne mais fait le travail en moins de trente secondes), vous attendrez quelques instants que la boite de dialogue nommée « Macro exécutée. » vous spécifie que le travail de remplacement est terminé. Vous n’avez rien à faire pendant les plus de quatre cents rechercher-remplacer que fait la macro. Juste regarder.
Le résultat n’est pas extraordinaire au début du texte ; vous me direz ce que vous en pensez pour la suite... Il n’y a, par définition, pas la moindre relecture puisque l’on part d’un texte brut d’OCR. Surtout, j’imagine que ce que j’ai lu, pour l’instant beaucoup trop en diagonale sur votre blog au sujet des « ſur-tout » puisse être résolu, même dans le cas d’une présence en fin de ligne. Ce cas spécifique n’est pas encore inséré dans le fichier Calc. Serez-vous de ceux qui lui apprendront ?
Voilà, c’était une petite avant première pour vous remercier encore de vous intéresser à ce merveilleux texte qu’est celui d’André Jacob Roubo. Je vais vraiment lire votre texte et passer du temps sur vos programmations pour en saisir la finalité. Je commenterai et vous répondrai véritablement après.
À très bientôt,
[editionAddition]
L’OCR fourni par Internet Archive est évidement automatique et, partant, est à l’image de la division des volumes et de leur reliure. Comme il est déjà spécifié dans Wikipedia, les fichiers PDF que les bibliothèques donnent à télécharger sont l’exact reflet de la reliure primitive de l’exemplaire photographié. Pour le cas d’Internet Archive le deuxième volume de cette reliure ne donne de texte intéressant que les deux pages de l’« Avertissement de l’Auteur » (1770) de le Seconde Partie. J’ai trouvé intéressant de remettre en fichier texte l’OCR brut de décoffrage d’Internet Archive divisé en parties et non en volumes. L’accès au répertoire de ces six fichiers est ouvert au public via le protocole HTTP, ce qui ne pose aucun problème au pesé de leur légèreté.
[/editionAddition]
Hors ligne
#6 09/04/2018 02:43
- jrbastien
- Membre
- Inscription : 19/03/2018
- Messages : 20
Re : OCR de l'Art du Menuisier
Je crois comprendre le fonctionnement de cette macro. C'est d'ailleurs la même idée que j'avais exécutée de façon manuelle dans Sigil sur les 2 premières parties de Roubo. Et mon nouveau programme en Python fait aussi du remplacement bien que son dictionnaire ne nécessite pas autant d'entrées qu'avec le OCR de l'Internet Archive.
Malheureusement, je n'arrive pas à obtenir une action. Je pense qu'il ne voit pas le fichier ouvert. Tout ce que j'obtiens c'est un rafraîchissement de la barre de boutons quand je clique sur "Rafraîchir la liste des fichiers texte (Writer)" Je ne vois pas non plus le code utilisé alors je vais devoir apprendre comment fonctionne les macros sous libre-office à moins que vous m'aidiez.
Vous aurez sans doute des difficultés aussi si vous essayez mon programme. Surtout avec la fonction cv2.findContours qui demande 2 ou bien 3 variables selon la version de Python utilisé.
Mais si vous voulez avoir un aperçu de l'OCR obtenu grâce à celui-ci. Il est ici: https://www.dropbox.com/s/3lu39am2mx066 … x.txt?dl=0
Vous remarquerez que les points forts de mon nouvel OCR sont la reconnaissance des numéros de figures, des s longs et le texte organisé en paragraphe sans saut de ligne inutile.
J'aimerais bien pouvoir le comparer avec vos résultats.
Il ne sera jamais possible d'obtenir une version parfaite sans relecture et corrections manuelles mais en combinant nos efforts, nous pourrons sans doute obtenir quelque chose de très potable.
Hors ligne
#7 09/04/2018 14:32
Re : OCR de l'Art du Menuisier
Bien cher Jean-René.
Un tout grand merci à vous pour vous être penché sur mon propre travail.
Je n’ai pas encore utilisé votre programme. Je dois installer un Linux correct, sur une machine acceptable ; ce qui demande ... un certain temps. Mais je me suis, évidemment, précipité sur votre OCR, pour en faire le comparatif avec celui d’Internet Archive. Pour l’instant (et notez le bien : pour l’instant seulement), je juge l’un et l’autre avec des avantages et des inconvénients des deux côtés. Il est aussi indéniable que ma liste de remplacements est très adaptée au passage choisi. J’ai établi une méthodologie pour cela et je suis en train de la rédiger. Ma macro fonctionne donc mieux pour le passage choisi dans l’OCR d’Internet Archive que pour le vôtre, non pour une question de programmation proprement dite, mais simplement d’entrées de liste. Mais vous devriez, quand même et sans doute, apprécier la présence des expressions régulières de LibreOffice pour ce qui regarde la gestion des fins de paragraphes...
Le Web REGORGE d’aide pour les macros de LibreOffice ou OpenOffice, à fortiori quand on accède à l’anglais. Le forum francophone est modéré par des gens au comportement qui frise l’abject ; l’anglophone est juste tenu par des gens normaux. J’ai déserté le premier depuis des lustres et j’intervenais encore récemment sur le second au sujet ... de choses que je pouvais aisément adapter d’un travail actuel... Je vous dis cela parce qu’il arrive, aussi, à mes petites crottes de se prémunir de styles... Dans tous les cas, la FAQ de developpez.com est encore une bonne source de solutions. Je reste évidemment et pour ma part votre serviteur pour la moindre de vos questions !
Partez du principe qu’un fichier ODF peut contenir ses propres macros mais que le programme lui-même possède aussi des bibliothèques qui lui sont propres. On peut donc avoir des macros à utiliser occasionnellement, ou inclues de manière permanente dans la suite bureautique.
On accède à la boite de dialogue ci-dessous par les menus :
« Outils » ► « Macros » ► « Gérer les macros » ► « LibreOffice Basic », ou, plus simplement, par le raccourci clavier [Alt] + [F11].
Toujours dans l’exemple ci-dessous, on voit que la bibliothèque « Standard » du fichier « rechercherRemplacer.Roubo.ods » (bibliothèque par défaut) ne contient qu’un module (« Module1 ») et que celui-ci possède à son tour deux procédures (macros), respectivement nommées « rechercherRemplacerParLot » et « listeFichiersOuverts ». Cliquez sur le bouton « Éditer » pour accéder au code.
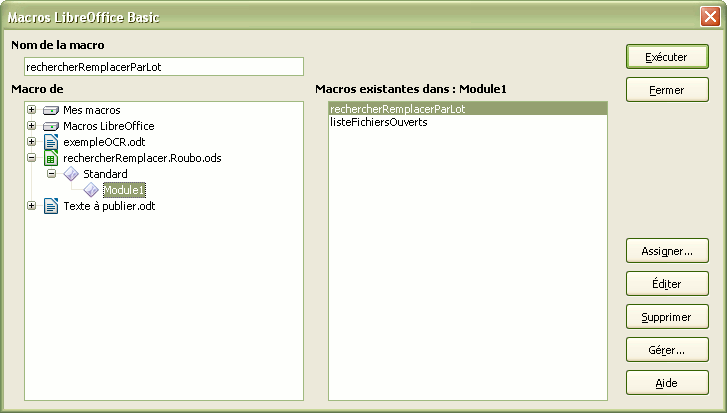
L’API de LibreOffice/OpenOffice est tout à fait spécifique à ce logiciel et n’a rien à voir avec celui de la suite propriétaire. Le strict Basic est, par contre, tout ce qu’il y a de plus classique. En général, j’essaie d’écrire du code qui soit lisible même par des gens qui ni connaissent que peu... Je veux dire que je ne crois pas être économe, tant en commentaires qu’en clarté de la présentation de mes encodages.
_________________________________
Il est, je suppose, acquis que vous ouvrez ce fichier comme pouvant exécuter les macros qu’il contient de façon sécuritaire. On passe pour cela par les menus : « Outils » ► « Options... ».
On clique ensuite sur les choix « LibreOffice » / « Sécurité » dans l’arborescence située à gauche de la boite de dialogue. Cliquer enfin sur le bouton « Sécurité des macros... » et opérer un choix (intuitif) en fonction de vos propres exigences. J’ai, pour ma part, tendance à choisir « Moyen » étant tout à fait entendu que je n’ouvre pas n’importe quoi de n’importe qui.
Les cellules B6 et C6 sont liées en une seule. Il est posé une « Validité » sur cette cellule. Les critères de celle-ci sont une plage de cellules, en l’occurrence la plage « rechercherRemplacerParLot.K2:K108 ». La colonne « K », qui, comme ses voisines, est masquée, contient la Liste des fichiers ouverts.
En sélectionnant la cellule B6, vous devez voir apparaître, sur la droite, une flèche vers le bas naturellement propre à indiquer une liste déroulante. Celle-ci contient toutes les URL des fichiers Writer présentement ouverts. L’endroit rêvé pour stipuler de manière très claire le fichier ciblé, en somme... L’endroit aussi où l’on se rend compte que les cibles peuvent être extrêmemement variées pourvue qu’elle soient ouvertes. Bonne découverte à vous.
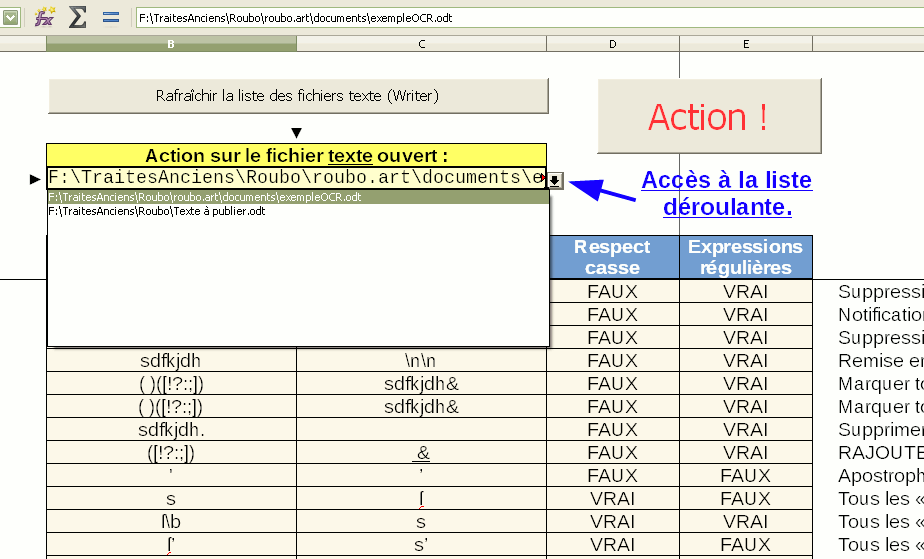
Vous aurez bien compris que si j’insiste sur ce type d’utilisation c’est parce que je suis convaincu que tout le monde n’a pas, comme vous et moi, des connaissances de programmation. Cette utilisation d’un tableur comme d’une énorme boite de dialogue, sans passer par l’utilisation, plus compliquée, d’une base de données, résout, il me semble, un grand nombre de problèmes pour des utilisateurs (tout aussi nombreux) qui claqueraient la porte à la vue d’une simple ligne de code...
Il est, de même, tout à fait acquis qu’il est nécessaire de faire une relecture humaine. Mais je suis même convaincu qu’elle doit même être plurielle et dépasser encore les simples deux correcteurs que nous sommes. Toutefois, nos deux efforts conjugués montrent déjà à nos potentiels lecteurs que nous avons une volonté commune d’aller dans un sens profitable à tous. J’aimerais, pour ma part, aller peut-être un tout petit peu au-delà de « quelque chose de très potable »... Mais notez encore que je n’ignore, en rien, le prix humain de ce désir ; il est aussi important que nos lecteurs potentiels sachent bien qu’à aucun moment, je ne ferai l’effort de me retourner pour leur donner une main secourable à une ascension que je sais longue et ardue. Si Rome ne s’est pas faite en un jour, on n’attaque pas, non plus, l’Everest en petite chemise. « Le mieux qu’il est possible » ; vous l’avez vous-même noté : même les Américains nous l’envient !

Hors ligne
#8 09/04/2018 18:26
- jrbastien
- Membre
- Inscription : 19/03/2018
- Messages : 20
Re : OCR de l'Art du Menuisier
Cher Sébastien merci pour votre support. J'ai trouvé le problème avec la macro (j'imagine que cela dépend de la version de LibreOffice utilisé).
Dans listeFichiersOuverts, remplacer
laCollection = starDesktop.components.createEnumerationpar
laCollection = starDesktop.getComponents.createEnumerationJe vais pouvoir analyser le résultats plus en détails et vous revenir avec mes commentaires.
Ps. Pour utiliser mon programme, vous pouvez installer Python sur Windows. C'est multi-plateformes.
Hors ligne
#9 09/04/2018 19:32
Re : OCR de l'Art du Menuisier
Je trouve cela très curieux, mais j’admets sans problème que l’API de LibreOffice, héritée d’OpenOffice, elle-même de StarOffice a quelque peu tendance à confondre les méthodes et les propriétés... Je suppose que votre version est spécifique à votre système d’exploitation, que j’imagine être une distribution Linux qui, comme c’est déjà arrivé, tente « d’arranger le coup » ou a peut-être compilé le logiciel en éliminant le superflu... Merci de ce signalement ; je viens de mettre le fichier à jour en ligne qui, avec la méthode getComponents plutôt que la propriété components a la gentillesse de fonctionner plus globalement...
Et si je puis me permettre, je sais bien que Python fonction sur vous-savez-qui ; mais de votre côté, vous ne semblez pas imaginer l’antiquité avec laquelle je travaille actuellement...
Bien à vous !
Hors ligne
#10 02/05/2018 14:50
- jrbastien
- Membre
- Inscription : 19/03/2018
- Messages : 20
Re : OCR de l'Art du Menuisier
Voici une mise à jour sur l'état de l'OCR. Après avoir développé un programme en Python pour faire l'extraction des blocs de texte, je n'étais pas encore tout à fait satisfait du résultat. J'ai donc décidé d'améliorer la reconnaissance à la source en apprenant à Tesseract le langage de Roubo et les polices de caractères utilisées dans cet ouvrage. Il y en a de 4 types:
Caslon (ou peut-être un typographe français que je ne connaît pas) régulier
Caslon italique
Petites capitales
Petites capitales italiques
Il a aussi beaucoup plus de ligatures que dans l'écriture moderne et certaines de ces ligatures n'ont pas de caractère Unicode officiel. Pour les afficher sur un ordinateur, il faut utiliser une police qui a ces caractères définis dans un plan complémentaire à usage privé. Comme ces caractères ne sont pas définis par la norme, leurs numéros de codage varient énormément d'une police à l'autre. Pour cet OCR, j'ai décidé d'utiliser ceux proposés par le MUFI (Medieval Unicode Font Initiave).
Voici la liste des caractères anciens que j'ai utilisés:
ſ s long U+017F
ſt s long - t U+FB05
s long - i U+EBA2
s long - s long U+EBA6
s long - s long - i U+EBA7
c - t U+EEC5
ff f - f U+FB00
fi f - i U+FB01
ffi f - f - i U+FB03
ffl f - f - l U+FB04
œ oe e dans l'o U+0153
Je n'ai pas encore fait les italiques et petites capitale mais les résultats obtenus avec la police régulière sont excellents. Quelqu'un qui utilisera les documents texte produits devra par contre posséder cette "pierre de Rosette" pour soit convertir les ligatures en lettres séparées soit les associer aux valeurs Unicode définies dans la police utilisée.
L’initiateur de ce site devra adorer puisqu'aucun s long ou ligature ne sera perdu.
À cette étape, j'aimerais bien obtenir des commentaires pour savoir si je fais fausse route ou bien si vous connaissez des polices qui imitent parfaitement bien le texte de l'ouvrage.
Une fois que je serai satisfait de tous les outils, je séparerai les images en chapitre pour les 4 parties de l'art du Menuiser et je produirai tous les OCRs en roulant mon programme. Ça devrait prendre plusieurs heures mais mon ordi ne devrait pas trop se plaindre!
Dernière modification par jrbastien (03/05/2018 15:56)
Hors ligne
#11 03/05/2018 18:59
Re : OCR de l'Art du Menuisier
Bonjour Jean René,
Si le fait de procéder à cet OCR semble pour le moins fructueux, c’est, je crois plus encore, que tu en fasses ici le témoignage qui me paraît on ne peut plus notable. Par là, tu permets à d’autres, par exemple pour d’autres ouvrages de la même collection (la « Descriptions des Arts et Métiers ») de récupérer ton travail, et donc, de s’économiser la réinvention de la roue. Je suis évidemment mille fois preneur de toutes tes expériences et ne te remercierai jamais assez pour cela !
Même si j’entends sans soucis que le type de Caslon convienne très bien pour cet OCR, je doute assez fort qu’il ait été celui employé par les imprimeurs de l’Académie Royale des Sciences (Jean Desaint & Charles Saillant) pour la « Descriptions des Arts et Métiers ». Il est clairement établit que l’on utilise encore à cette époque, et jusqu’à La Révolution, le « Romain du Roi », même si, encore, il est tout aussi acquis qu’il n’évolue plus après 1745. Ceci me semble corroboré par le fait que cette typographie a, précisément, été élaborée sous l’égide de l’Académie.
Même si c’est très simplement réversible, je ne suis pas certain qu’il faille se contraindre à utiliser de UTF8 dans la « Zone à usage privé » et ceci pour deux raisons principales :
Cela contraint à n’utiliser le texte qu’avec une seule police de caractères.
Cela réduit considérablement la facilité d’indexation sémantique, alors que c’est le but premier d’une version numérique textuelle. Si je cherche un mot dans tout le texte et que celui-ci contient un caractère spécifique à une ligature, je suis obligé de le taper dans ma zone de recherche, donc d’en connaître le code ou de jouer avec du copier-coller.
Le s long, les o-e ou a-e liés, minuscules ou majuscules, sont standardisés par UTF8 depuis des lustres et ne posent pas de problème.
Il y a encore des différences de recherche sémantique selon les logiciels. Par exemple, si je prends cette page et que je cherche, avec le navigateur Web Firefox, le mot « Menuisier », il ne le trouvera qu’une seule fois, naturellement dans le titre. Dans le même contexte, si je cherche le mot « Menuiſier », donc avec s long, il le trouvera sept fois ; et s’évitera le titre. Mais certains logiciels sont plus évolués. Copions-collons ce texte dans LibreOffice et cherchons le mot « Menuisier » OU « Menuiſier » ; il le trouvera huit fois, étant bien entendu qu’il soit spécifié de ne pas prendre la casse en compte...
Il y a encore des polices de caractères qui gèrent très bien, dans un certain contexte, les ligatures ou les styles de chiffres, par exemple anciens... Exemple : avec LibreOffice et, bien sûr installée, la police de caractères « Linux Libertine G », taper, en gros caractères, les mots « La perfection des Menuiſiers en 1769. ». La ligature entre le s long et le i se fait normalement ; mais pas celle entre le c et le t de « perfection ». De même, « 1769 » est écrit de manière moderne, avec des chiffres de mêmes hauteurs et alignés sur la même base.
Sélectionner cette même phrase et la copier-coller juste en dessous pour comparaison. Réopérer une sélection et RAJOUTER au nom de police de caractère la mention « :hlig=1&onum=1 »
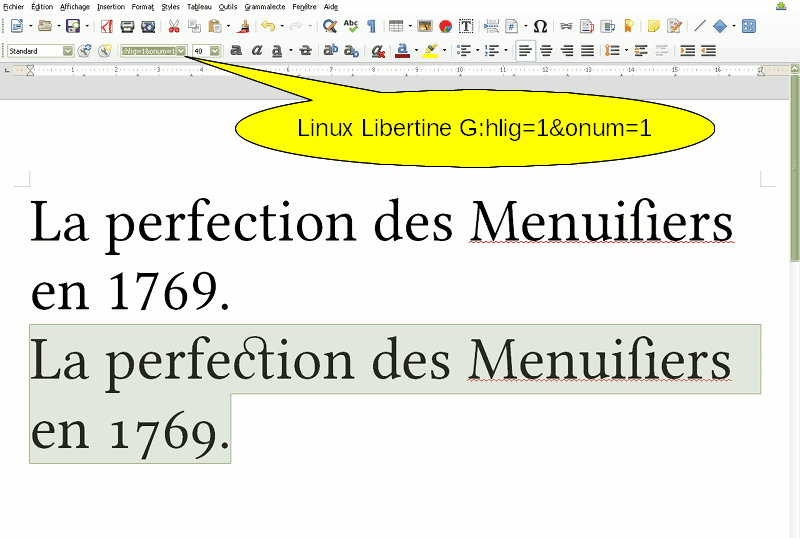
Étonnant non ??? Voilà ; on demande à une police de faire son travail, et elle le fait, je le crois, franchement plutôt bien. Les navigateurs Web actuels ne sont pas capables de gérer ce genre de choses, plutôt de l’ordre du traitement de texte [correction plus bas]. Mais nous aurions à sortir un PDF, il serait tout à fait à la hauteur typographique de ce que je crois que l’on peut demander à un texte qui reste contemporain dans sa production. J’ignore ce qu’il en est des lecteurs d’e-books, mais je ne serais pas surpris qu’il en aille ici comme pour les navigateurs Web tant le format qu’ils utilisent est proche. On trouve les spécifications d’utilisation de Linux Libertine dans ce fichier PDF. Pour ma part, je ne crois pas une bonne chose d’aller trop loin dans le détail « codé en dur » et il en va de même, par exemple et en illustration, pour les petites capitales. J’aurai tendance à les écrire, en minuscules normales, sachant qu’au même titre que l’italique, il s’agit bien là d’un enrichissement de caractères et non pas d’un codage particulier, forcément plus ou moins spécifique à une fonte. Que le s long soit codé en dur est normal ; c’est un caractère spécifique presque au même titre que les signes diacritiques. Les ligatures me semblent nettement plus relever de l’enrichissement typographique, à fortiori parce que les coder en dur va perturber considérablement l’indexation sémantique (typiquement [Ctrl] + [F]) déjà assez secouée par le seul s long...
Tu notes encore que je ne jure pas que par Linux Libertine... Qu’on me donne une autre police TTF, libre, plus proche du Romain du Roi et je l’adopterai immédiatement. Simplement, je n’ai fait que peu de recherche sur le sujet, étant, à l’heure actuelle, et tu le sais bien, plutôt focalisé sur les Planches.
Dans tous les cas, reçois encore toute ma gratitude pour témoigner en ce lieu de tes recherches, étant bien entendu que mes propres choix ne seront sont pas forcément les tiens en fonction de tes aspirations propres.
Dernière modification par smcj (05/05/2018 14:33)
Hors ligne
#12 04/05/2018 01:06
- jrbastien
- Membre
- Inscription : 19/03/2018
- Messages : 20
Re : OCR de l'Art du Menuisier
Sébastien, tu me sauves la vie ici. J'ai vraiment cherché cette police et tout ce que j'avais trouvé c'était Caslon (cet anglais qui n'a fait que s'approprier le travail de Grandjean). Dommage que Louis XV s’intéressa plus à l'entretien de ses nombreuses maîtresses qu'à celle de la défense de la colonie Nord-Américaine car peut-être qu'aujourd'hui le Romain du Roi serait plus connu...
Faire revivre cette police en version libre est un autre projet auquel je m'attaquerai peut-être un jour...
Grâce à toi, j'ai aussi pu trouver que la police italique Fournier a été crée directement à partir du Romain du Roi. C'est celle qu'il me faut pour apprendre à Tesseract.
Car vois-tu, il y a deux façons de montrer à ce logiciel comment faire son boulot : lui faire lire des dizaines d'images de pages contenant toutes les lettres du jeu de caractères et corriger chaque caractère mal reconnu ou bien lui passer un simple texte qu'il lira à l'aide de la police à reconnaître. Comme le texte n'est pas une image, aucun caractère n'est à corriger. La deuxième méthode est évidemment beaucoup plus facile. Mais la police utilisé doit être parfaite pour obtenir un bon taux de reconnaissance par la suite.
La raison pour laquelle je me suis attardé à préserver les ligatures originales n'est pas que je voulais préserver à tout prix la forme d'écriture en usage à l'époque mais plutôt que Tesseract voit ces ligatures comme un seul caractère. Puisque ces lettres n'existent pas dans un jeu de caractères UTF-8 (et plus précisément celui du langage utilisé), il retourne n'importe quoi. Tu as sans doute remarqué comment il était troublé par les mots « assemblage », « architecture ». Ajouter les ligatures inexistantes au jeu de caractères corrige ce problème. C'est d'ailleurs cette découverte qui est la clé de l'amélioration de l'OCR.
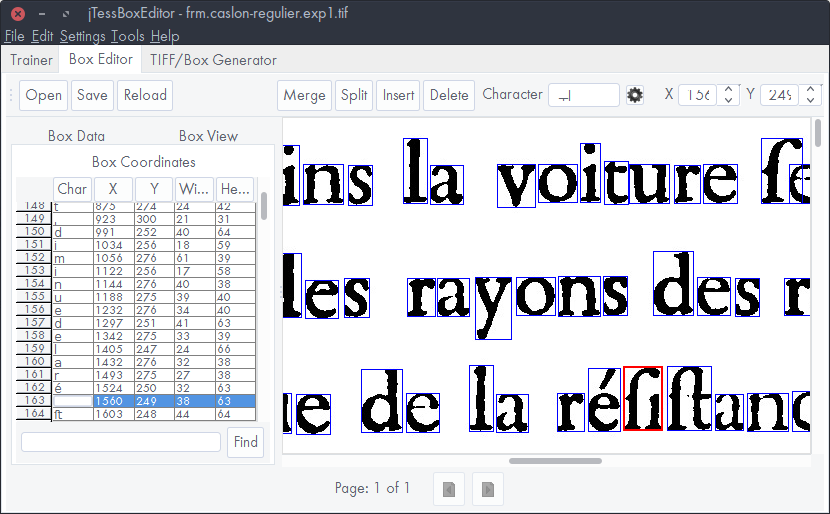
Mais comme on l'a déjà discuté, une simple recherche/remplacement peut mettre le texte à la convenance de chacun. Donc aucun problème ici.
Et je n'avais pas pensé à cela mais oui tout vieil ouvrage utilisant le Romain du Roi pourra être reconnu facilement par la suite.
Pour ce qui est de ton truc pour afficher les ligatures dans LibreOffice, je ne le connaissais pas. C'est fantastique !
Hors ligne
#13 04/05/2018 13:36
Re : OCR de l'Art du Menuisier
Faire revivre cette police en version libre est un autre projet auquel je m'attaquerai peut-être un jour...
Je n’ai fait aucune recherche sur le sujet, mais je suis surpris que ça n’ait pas été déjà au moins projeté. Je ne te dis pas à quel point je juge ce genre de choses utile à la communauté... À fortiori pour quelqu’un qui a, ici ou là, largement prouvé son intérêt pour la typographie...
La raison pour laquelle je me suis attardé à préserver les ligatures originales n'est pas que je voulais préserver à tout prix la forme d'écriture en usage à l'époque mais plutôt que Tesseract voit ces ligatures comme un seul caractère.
C’est nettement plus clair pour moi maintenant et parfaitement compréhensible d’un point de vue technique. Merci à toi de cette explication.
Et je n'avais pas pensé à cela mais oui tout vieil ouvrage utilisant le Romain du Roi pourra être reconnu facilement par la suite.
Eeeuuhhh ; là c’est juste énÂÛrme. Je ne sais pas si tu te rends compte de ce que tu apportes à la communauté, mais le contenu de la « Description des Arts et Métiers », ce n’est quand même pas un détail... Quand on voit comment Gallica, avec les moyens qui sont les siens, traite, par exemple et pour ne citer qu’elles, les ligatures c-t dans son OCR sur le seul Menuisier en Carrosses, on se dit qu’ils feraient bien de te lire sur le présent forum...
Pour ce qui est de ton truc pour afficher les ligatures dans LibreOffice, je ne le connaissais pas. C'est fantastique !
Quelquefois au-delà... Prendre une Planche de ce type, bourrée de fractions et se servir du tableur Calc de LibreOffice pour en faire la transcription, en Linux Libertine et ses options-« frac »-et« onum »-qui-vont-bien pour obtenir, au final, cette petite merveille qui ne fait pas 60 kilo-octets, c’est juste... épanouissant...
Hors ligne
#14 04/05/2018 15:08
- jrbastien
- Membre
- Inscription : 19/03/2018
- Messages : 20
Re : OCR de l'Art du Menuisier
Selon ton expérience Sébastien, est-ce que c'est Gallica qui a le meilleur OCR? J'aimerais pouvoir faire quelques statistiques et comparaisons avant de lancer mon OCR sur des milliers de pages. Je regarde le lien que tu m'as envoyé et il y a des choses que Gallica fait très bien:
Il y a peu de petites saletés qui sont capturées et reconnus comme des signes de ponctuations (apostrophes, guillemets, virgules).
Les mots coupés par des tirets en fin de ligne sont bien reconstitués en un seul pour former des lignes complètes.
Très bon taux de reconnaissance sur tous les mots ne contenant aucune ligature.
Les choses qu'il fait moins bien:
La reconnaissance des ligatures (je t'ai expliqué pourquoi)
Discerner le s long et le f. Dans les peu de tests que j'ai fait, j'avais 100% de succès avec mon OCR!
La reconnaissance des chiffres (leur OCR n'a sans doute pas appris la vieille forme d'écriture avec des chiffres positionnés à différentes hauteurs)
Le positionnement de la référence à la planche par rapport au texte.
Pour ma part, je vois que je capture un peu trop de saletés (ou bien je dois trouver comment les nettoyer). Je dois aussi appliquer plus de logique dans mon code pour mieux positionner tous les blocs de texte (incluant la référence de planche qui devrait être placée en début de paragraphe). Et je devrais reconstituer les phrases en fusionnant le dernier mot de la ligne et le premier de la suivante. Puis le comparer au dictionnaire pour déterminer si le tiret doit rester ou pas ou si ce même tiret a été lu comme autre chose et doit être enlevé.
Comme tu vois, ce sont de beaux défis. Je réalise maintenant que je me suis lancé dans un projet de longue haleine.
Hors ligne
#15 05/05/2018 14:30
Re : OCR de l'Art du Menuisier
Mon expérience en matière d’OCR n’est pas référentielle ; la tienne est supérieure. J’ai besoin, pour ce genre de choses, de m’y plonger complètement, ce qui n’est pas le cas. Mais Gallica n’a fait d’OCR sur le texte de Roubo que pour la Première Section de la Troisième Partie, donc que pour le Menuisier en Carrosses ! Donc, de toutes façons, les autres restent à faire...
À partir du moment où tu te lances là-dedans, de manière très spécialisée puisqu’il est entendu que c’est « une niche », tu finiras par forcément dépasser les résultats de Gallica. Tu as, dans le présent fil de forum, très bien expliqué que l’axe principal du problème tourne autour de la fonte, dont il est, je crois, acquis que c’est le Romain du Roi. Se plonger dans l’étude de cette fonte, c’est commencer par lire des choses sur l’excellent site de Jacques André au sujet de Sébastien Truchet, comprendre comment sont construite les Planches publiée (et parfois réinterprétées) par le tout aussi prolixe Rocbo. J’en passe et forcément des meilleures, juste parce que je sais bien que je dois me concentrer sur autres choses actuellement. Par exemple, même la bibliographie de Jacques André ne donne pas accès au texte de la description des Planches de Truchet. Il permettrait, pourtant, d’aider énormément à la re-conception d’une fonte libre...
Par ailleurs...
Les navigateurs Web actuels ne sont pas capables de gérer ce genre de choses, plutôt de l’ordre du traitement de texte.
Correction votre honneur... Je vous dis des bêtises ; profondément, sûrement, certainement, sans le moindre doute, du genre monstrueuses et pas du tout fondées... En regardant cette page, il m’a sauté aux yeux que les chiffres des années (1769-1775) n’étaient pas alignés. Je sais que Wikimedia utilise Linux Libertine, à fortiori parce que leur logo est inclus dans la zone UTF-8 à usage privatif. J’ai cherché un peu plus de deux minutes et suis tombé sur cette page que je te communique, tant je crois que le CSS d’un e-book peut en retirer les fruits... Pour une page Web, c’est évidemment la même chose, étant bien entendu que « Linux Libertine G » soit bien présente sur ton système d’exploitation. Démonstration ici dont la lecture du HTML et de sa partie CSS incluse peut être quelque peu instructive...
Hors ligne
Pages : 1